
Your Coding Agent Doesn't Need a Better Model. It Needs a Better Workflow.
Scaffolding dominates model choice for coding agents. Here are four practical changes that made my agents actually useful.
A few months ago I was coaching a dev team that had one very vocal skeptic. His take: AI needed more babysitting than it was worth. He’d tried GitHub Copilot, gotten mediocre results, and written the whole thing off.
We didn’t argue with him. Instead, we showed him how to set up copilot instructions, walked him through better tooling to interface with Copilot’s agent, and gave him a methodical way to prompt that reduced the rework noticeably. Within a few weeks, the skeptic had converted into a power user. He wasn’t complaining about babysitting anymore. He was asking questions like when to use premium models versus non-premium. Same model. Same codebase. Same developer. The difference was entirely workflow.
A systematic study of 80 SWE-bench approaches found the same thing: scaffolding dominates over model choice. When the SWE-bench team held scaffolding constant and compared frontier models head-to-head, Sonnet 4 and GPT-5 scored within a point of each other. The model barely matters. The workflow around it matters enormously.
Four things moved the needle for me.
1. Scope Tasks to One Thing
A SWE-Bench Mobile study tested 22 agent-model configurations and found up to a 6x performance gap from the same model in different scaffolds. One of the biggest factors? Task scope.
When I give an agent a GitHub issue that says “refactor the auth module and also update the API docs and fix that flaky test,” it produces garbage. When I give it “fix the race condition in auth/session.ts where concurrent refresh tokens can corrupt the session store,” it produces something I can review in five minutes.
I’ve started writing issues specifically for agents. One clear problem. Reproduction steps if applicable. Pointers to the relevant files. That’s it.
This was the fastest change I made. No new tooling required. Just better issues. On teams I’ve coached, getting everyone aligned on how to write agent-ready issues has been the single quickest win.
2. Write an Operating Manual, Not a Wish List
Your agents.md (or CLAUDE.md, or whatever your tool calls it) is the single highest-leverage file in your repo. But most of them read like vague wish lists.
GitHub analyzed over 2,500 repositories with these files and found a clear split. The repos getting consistent results shared specific traits: executable commands with exact flags, real code examples instead of prose descriptions, and explicit three-tier boundaries (always do, ask first, never touch).
Here’s what a good one looks like in practice:
## Commands
- Test: `npm run test -- --coverage`
- Lint: `npm run lint:fix`
- Build: `npm run build`
## Boundaries
- ALWAYS: run tests before committing
- ASK FIRST: changes to database schemas
- NEVER: modify CI pipeline filesCompare that to “Please follow best practices and write clean code.” One gives the agent something to execute. The other gives it nothing.
Anthropic’s context engineering guide makes the same point: context is a finite resource. Every token your agent spends figuring out your build system through trial and error is a token not spent on the actual task. Tell it upfront.
3. Add Verification Loops
This is the single most effective change I’ve made. Instead of letting the agent submit code and hoping it works, I make it check its own work before I ever see it.
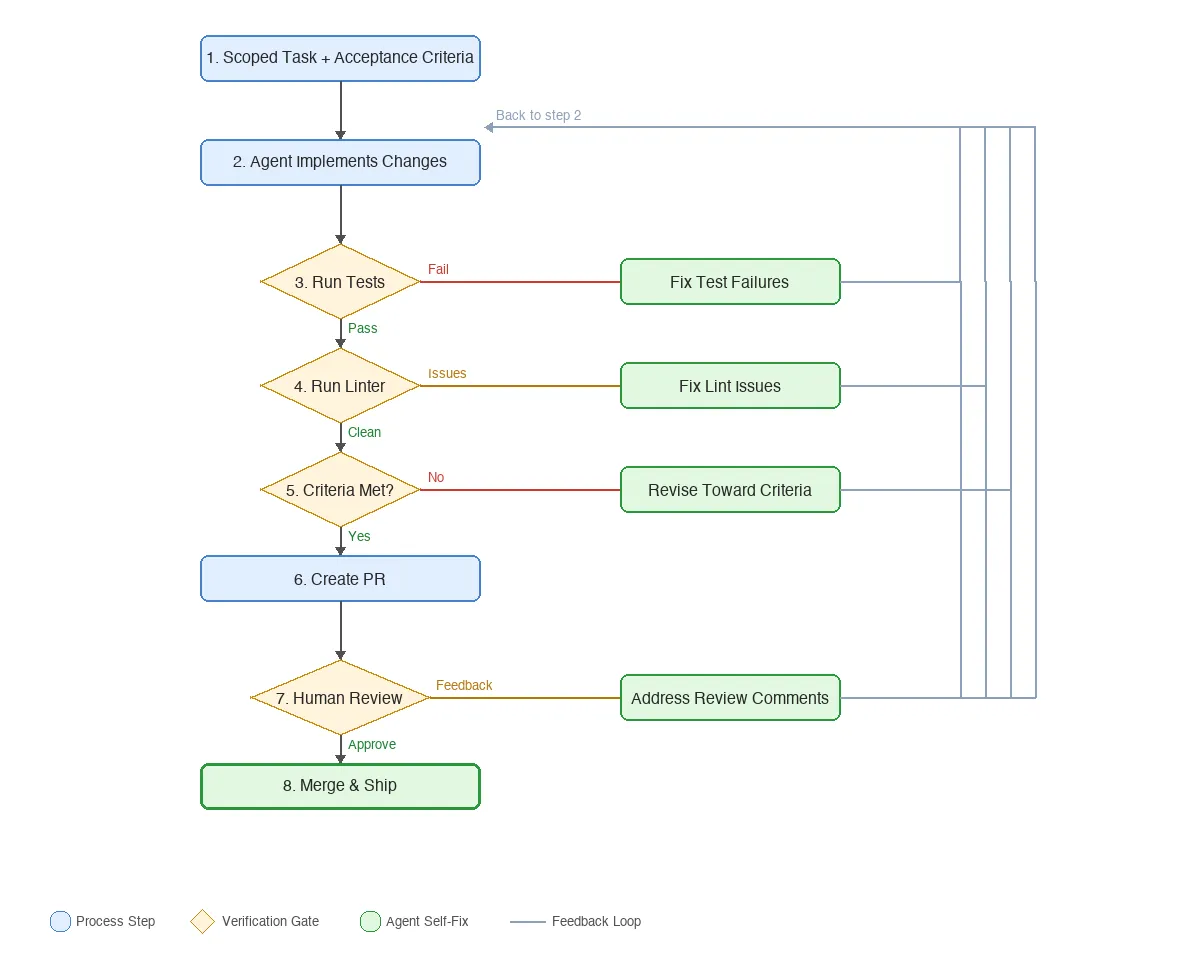
The pattern is simple: after the agent writes code, it runs the tests. If they fail, it fixes and re-runs. Then it runs the linter. If there are issues, same thing. Then it checks whether the original acceptance criteria are actually met. Only after all three gates pass does it create a PR.
A 2025 study on self-improving coding agents found that letting an agent iteratively refine its own pipeline (including its verification steps) boosted SWE-bench performance by 17 to 53 percent depending on model and task. Before I added verification loops to my own setup, maybe half the PRs my agents opened were merge-ready. After, it’s closer to 80 percent. That’s a gut estimate, not a measured metric, but the difference was obvious in review load.
In practice, I encode this directly in the instruction file:
## Before Opening a PR
1. Run `npm run test` and fix failures (max 2 attempts, then stop and explain)
2. Run `npm run lint:fix` and commit any changes
3. Re-read the acceptance criteria from the issue and verify each one is met
4. If any criterion is not met, revise and restart from step 1The attempt cap in step one matters. You want the agent to bail out rather than spiral into increasingly creative (and wrong) fixes. And step three catches the sneaky failures where tests pass but the agent solved the wrong problem.
4. Close the PR Feedback Loop
Most teams review agent PRs, leave comments, and then manually fix whatever the agent got wrong. That’s a missed loop. The agent can do that work.
The tooling for this has gotten surprisingly good. GitHub Copilot now does PR reviews, and they don’t have to be shots in the dark. Your copilot-instructions.md file shapes what Copilot looks for and how it responds, the same way it shapes code generation. You can tell it to flag missing test coverage, enforce naming conventions, or check that acceptance criteria are met. The review reflects your standards, not generic suggestions.
You can also run these reviews locally in VS Code with the GitHub extension’s PR Review button. No context switching to the browser, no waiting for CI. Just open the PR, click review, and Copilot walks through the diff with your instructions in mind.
When you get review feedback, you can tag @copilot in a PR comment and it will push a fix. Other agents like Claude Code and Codex can do this too. The review becomes a conversation: you leave a comment, the agent addresses it, you re-review.
Paired with verification loops, most agent PRs converge in one or two review cycles. The agent catches the mechanical stuff itself; I focus review on design and intent. For teams I’ve coached, this is where the biggest mindset shift happens: treating the agent like a junior dev who can take direction, not a black box that either works or doesn’t.
The takeaway
If scaffolding matters several times more than model selection, the teams getting the best results aren’t the ones with the biggest AI budgets. They’re the ones with the most disciplined engineering practices.
Pick one of these four changes, implement it this week, and measure the difference. I think you’ll find that your “underperforming” model has been capable of much more all along. It just needed a better workflow to show it.